The Problem with Vibecoding
Code is not the product. The system is.
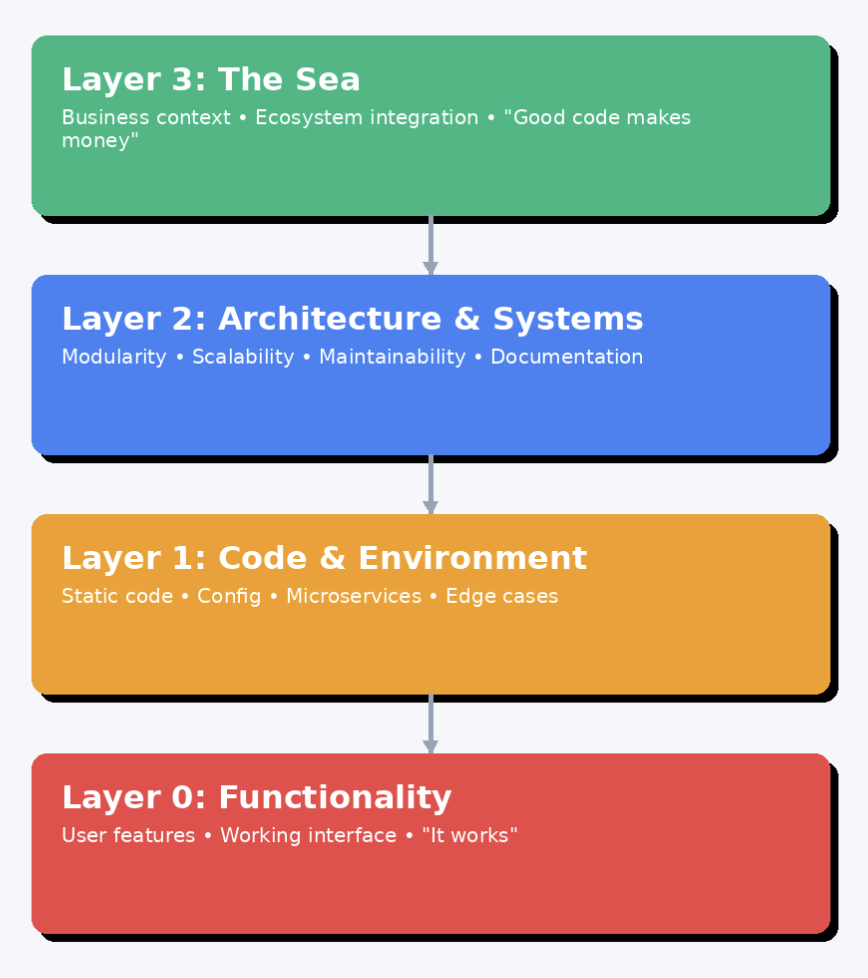
Claude vibecoded this diagram.
Vibecoding, a term first coined by Karpathy, is a software development practice that leans heavily on AI to generate code from natural language prompts (but you probably knew that!). Instead of manually writing every line, the developer’s role shifts to guiding an AI assistant, steering it, “by vibes” without ever interacting with it directly. It wouldn’t be wrong to say that entire startups have sprung up (or at least benefited a lot ) around this coding paradigm, Lovable, Replit, v0, among others, empowering (yes, for once not just as a startup buzzword!) thousands of people to create and deploy code. AI is doing for software what Gutenberg's printing press did for writing: collapsing the cost of creation and unleashing a flood of niche, personal output.
But as some vibecoders have learned the hard way (including many of my own recent sessions that inspired this article) vibecoding can only take us so far. While it’s an infinite improvement over having no code at all, it comes with some very real limitations.
Vibecoding works great for small projects, one-off apps, and minor tweaks to existing large repositories. But the larger the project, and the longer you spend building it, the more likely the whole thing is to fall apart. The core issue, I think, is that vibecoding treats the code as the sole artifact of interest. Or rather, even less than that: it treats the functionality produced by the code as the only thing that matters. That’s an extremely limiting perspective on what we’re actually creating.
Just to be clear, this isn’t meant as a takedown of vibecoding or vibecoders. My hope is that readers will find something here they can use to approach their own vibecoding sessions more thoughtfully, and even if you’re a purely human coder, maybe you’ll walk away with a sharper perspective on what it actually means for code to be good. None of what I’m about to say is radical; most of it is already baked, explicitly or implicitly, into coding best practices. But as we move through this paradigm shift toward AI-generated code, it’s worth reminding ourselves of these fundamentals.
Code is not a static artifact. The product is not supposed to be code but a system, and it has to be understood and designed as such.
To really understand what we’re doing when we “write code,” I’m going to start with the narrowest definition of a software product, at layer 0, and then zoom out until we’re looking at it in its broadest sense, as a system.
Layer 0 - Functionality
This is where vibecoding lives: the raw functionality of software. A working interface, a visible feature, an outcome the user can interact with. At this layer, only the outcome matters: what is delivered, not how it is made.
Layer 1 – The Code & Its Immediate Environment
1a — The Static Artifact
The machinery behind Layer 0. This is the code itself, the instructions that produce the functionality. Vibecoding at this level focuses on the immediate implementation: how the code works right now, not how it will behave or evolve over time.
1b — Surrounding Artifacts
This is simply 1a at a broader scale. In real-world domains like data engineering, machine learning, and DevOps, code is just one part of a larger system that also includes data, configuration, hardware, and external services. Vibecoding tends to fixate on narrow software use cases, but serious systems have tightly coupled dependencies: datasets, configurations, hardware specs, API contracts. In ML or data science especially, much of the “code” actually lives in non-code form.
1c — Correctness & Consistency
Not just "it runs," but "it runs reliably." That means handling edge cases, producing predictable outputs, and avoiding coincidental correctness: the "broken clock" problem where code happens to work for the test case but not the domain.
Correctness requires more than matching outputs under specific conditions. The code's structure needs to map to the actual logic of the problem it solves. When that correspondence breaks down, we get mimicry: surface-level functionality that reproduces expected behavior without capturing the underlying rules. The code appears to work until it encounters a novel situation, then fails unpredictably. All abstractions leak eventually, but the goal is to shrink that gap as much as possible.
Tests can't catch this because they confirm behavior, not structure. Only code that actually embodies domain logic can adapt to new requirements without collapsing.
The drift between appearance and reality often shows up in what the code does between inputs and outputs:
- Variables with inconsistent or misleading intermediate states
- Logs that describe what the code technically did, not what happened in business terms
- Error handling that swallows exceptions to keep the demo running
- Metrics that measure activity rather than outcomes
These details constitute the system's real behavior. In AI-generated code, they frequently go unexamined because the AI won't surface them unless specifically asked, and the "vibe" of the interaction doesn't prompt that level of scrutiny. The interface looks solid while the internals quietly diverge from the intended model or are not informed by the broader context of their use anyways. Over time, this silent misalignment corrodes reliability, complicates debugging, and blocks scalability (where we enter Layer 2).
Human developers catch these issues by deliberately inspecting runtime behavior: reading logs, adding instrumentation, tracing state changes. Vibecoding removes the friction of writing code but also the natural checkpoints where such inspection happens. Without deliberate effort to recreate those feedback loops, brittleness accumulates until the system can no longer be trusted.
Layer 2 – Structure & Operability
2a — Architecture, Modularity & Scalability
The ability to change, replace, or scale parts of the system without rewriting the whole thing. This is where higher-level software architecture principles kick in such as OOP, modularity, design patterns, separation of concerns. The question shifts from “Is my code tactical?” to “Is my code strategic?”
Does the system allow itself to be built upon? Can components be reused or swapped out without touching the rest? Can it scale both in complexity and in load? Well-defined interfaces and loose coupling create modular, evolvable systems instead of brittle code that resists change.
2b — Understandability & Human Operability
Even the best architecture fails if no one can work with it. Whether it’s human developers today or AI agents tomorrow, the system needs to be clear, navigable, and easy to modify without accidental breakage.
This is the point where we leave the machine’s world and step into ours. Can we extend it, scale it, push it to the brink without it falling apart? That’s where documentation, comments, meaningful naming conventions, and version control come in. These aren’t afterthoughts but part of the design. A codebase isn’t truly operable unless people can reason about it quickly and confidently.
Layer 3 – The Sea
3a — Business & Ecosystem Context
“Good code is code that makes money.”
This is the code’s ultimate reason for existing: delivering value, fitting into a broader network of systems, and adapting to external forces. This layer decides whether the system matters at all.
Level 3 is a scary world: one of product managers and Jira boards, but also profits and ethics. It’s the widest scope of code as a system; it’s the world itself. I won’t yap on, but the key point is this: the stronger your lower layers are, the easier it is to place code into larger systems with minimal friction.
From this framework, we can start thinking about code not just in tactical terms but in strategic ones. Code is not simply the outward behavior it produces, and it shouldn’t be designed based solely on that functionality. Code is holistic.
Right now, vibecoding mostly operates at the first level: simple code for small applications, especially front-end work, and, to a lesser extent, in more complex contexts like Layer 1b.
That’s where things get interesting, because Layer 1b is the point where AI can start touching not just the code, but the datasets, configurations, and other inputs that shape how that code runs. And since most AI agents are themselves ML-based systems, this opens the door to self-recursive setups - agents that can adjust the very parameters or training data that define their own behavior, and then re-run the cycle. That’s the kind of research-driven loop I’m excited about. But for now, the higher rungs we need for this and our own use cases are still a long way off.
Currently, the AI coding ecosystem splits into two camps:
-
Lovable, Replit, v0, etc. built for one-off uses, static and targeted. As Amjad Masad has put it, this is where you can build an app or workflow with an audience of one.
-
Cursor, ClaudeCode: Often geared towards more technical users, not strictly just “vibecoding” platforms, but they can be used that way. They support a full spectrum of interaction: writing code character by character, accepting inline suggestions, running commands, or generating entire files in a single step. Along this spectrum, you can also reach into higher layers, making architectural requests, applying precise code changes, while drawing on prior context and pre-set rules from memory.
Improvements are coming. Both scaffold developers and LLM providers know about the gap I’ve described. Claude, OpenAI, and others are actively competing to be the better coding partner. Many people think the bottleneck is just scaling context windows so larger codebases can be understood at a “big picture” level. And yes, that’s a huge part of it, but not the whole issue.
Simply feeding the AI more data with larger context lengths or packing context more efficiently won’t get us to true system-level coding. LLMs will need to understand what it means to produce good code over long time horizons - which, if you’re familiar with RL, you know is easier said than done. Integrating codebases with external documentation, Slack, Jira boards, and other sources of implicit business context is a step in that direction.
Model developers are already responding to this: AI systems are now trained with agent scaffolds like Cursor in mind, and you can feel it in use. The other day, I LLM-generated a script to apply a change across a large dataset, and it quietly included a “dry run” flag so I could check the results first. The script assumed I would review it, decide, and only then let the change run. The code, the data, and my judgment were all moving together inside the same system and the AI model recognized it.
I’m optimistic about a future where most code can be abstracted away, leaving us to work in instructions while AI systems handle the underlying details. Humans may need to look at code only 1% of the time - if that. But will this make code any less of a system? Absolutely not. Layer 3 will still exist, and at Layer 2 systems will increasingly be designed for other AI agents to understand and extend rather than for humans alone.
These layers are only one way of seeing the system. Other dimensions, interactions, and artifacts extend far beyond what I’ve mapped here. But the direction is clear: code is never the product by itself. What we build, and what ultimately matters, is the system that surrounds it.