Flex Attention Explained
Bridging Performance and Flexibility in Transformer Attention Mechanisms
Launched in early 2024, FlexAttention enables researchers to modify attention mechanisms without writing complex GPU kernels, while maintaining FlashAttention's performance benefits. This post examines FlexAttention's core functionality and implementation details at a high level. We'll explore how it integrates with PyTorch's compilation system and discuss current technical limitations and optimization considerations. While the MLP layer remains the primary bottleneck in most transformer systems like LLMs, the quadratic O(n^2) scaling of self-attention mechanisms becomes increasingly problematic as sequence lengths grow. This makes efficient attention implementations essential for handling longer sequences.
To understand how FlexAttention builds upon and extends FlashAttention's innovations, we first need to look the core principles of FlashAttention itself. For a comprehensive understanding of FlashAttention, readers can refer to Aleksa Gordic's incredible explanation of the technique. In simple terms, the primary source of latency in large-scale machine learning systems is not the mathematical operations (Tensor Ops) themselves. Instead, the main bottleneck comes from I/O (Input/Output) operations, specifically reading and writing data, model parameters, or gradients to and from memory.
GPUs have a memory hierarchy, with the fastest but smallest memory cache closest to the arithmetic logic units (ALUs). Loading data, such as QKV (Query, Key, Value) matrices, from main memory into these GPU caches is a time-consuming process. This data transfer bottleneck is a fundamental hardware constraint, limited by both the physical distance between memory regions and ALUs and the maximum speed at which data can move between them.
In a vanilla attention mechanism with no hardware optimizations, each step would require separate read/write operations. First, we compute the Query-Key matrix product to generate the attention scores and write the result to the cache. Then we repeatedly load and store the data for each operation: scaling, dropout, and softmax. Each of these steps forces data movement between memory layers, creating unnecessary I/O operations that significantly impact performance.
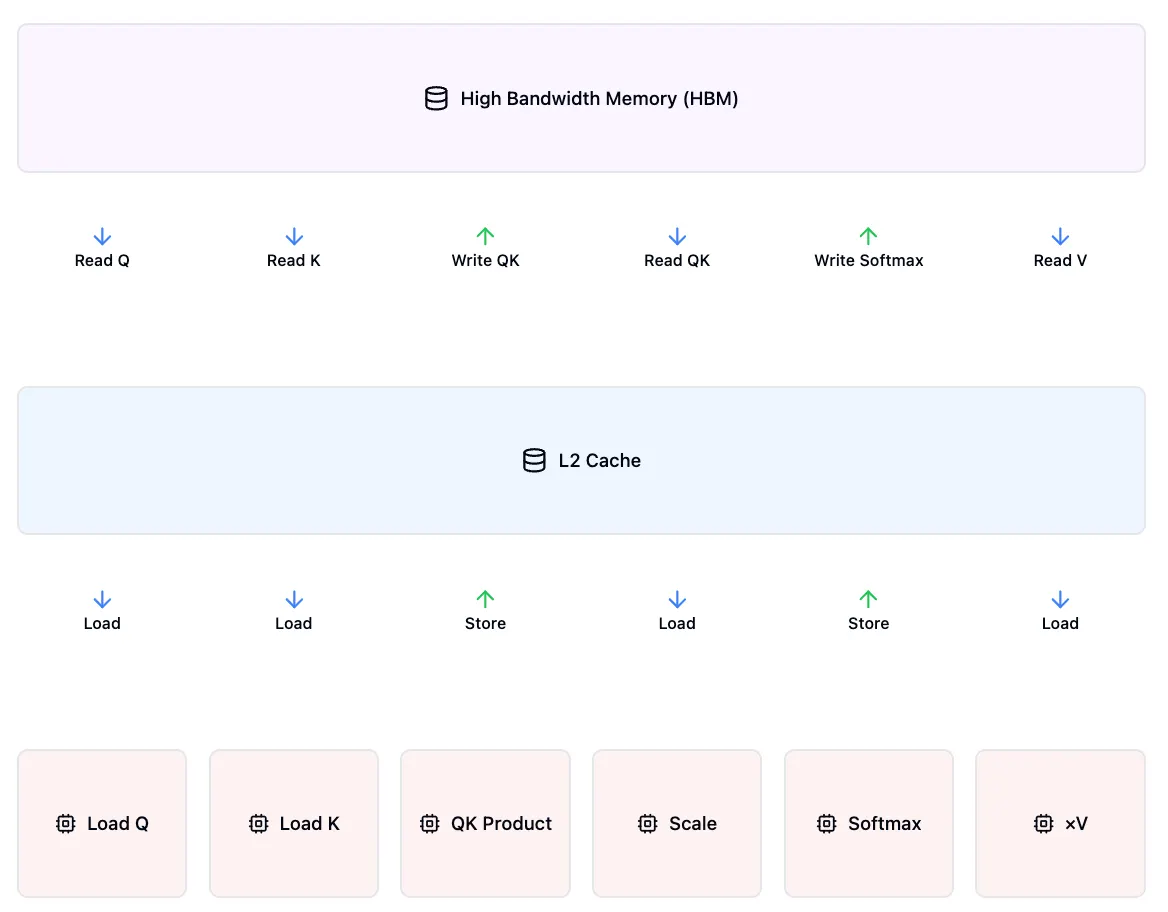
Simplified vanilla Attention with no hardware optimizations.
FlashAttention's key innovation is processing attention by dividing Query and Key matrices into smaller chunks, which are distributed across GPU blocks for parallel processing. Each chunk is loaded into the cache once, where multiple tensor operations are fused into a single execution pass (a "flash") before writing back to memory once. Even the softmax computation -- otherwise a bottleneck requiring the complete sequence of attention scores -- is handled through the online softmax technique that preserves the chunk-based parallelizability while maintaining accuracy in computation. This optimization of memory operations and parallel processing addresses one of the key bottlenecks in modern machine learning systems, resulting in substantial performance gains.
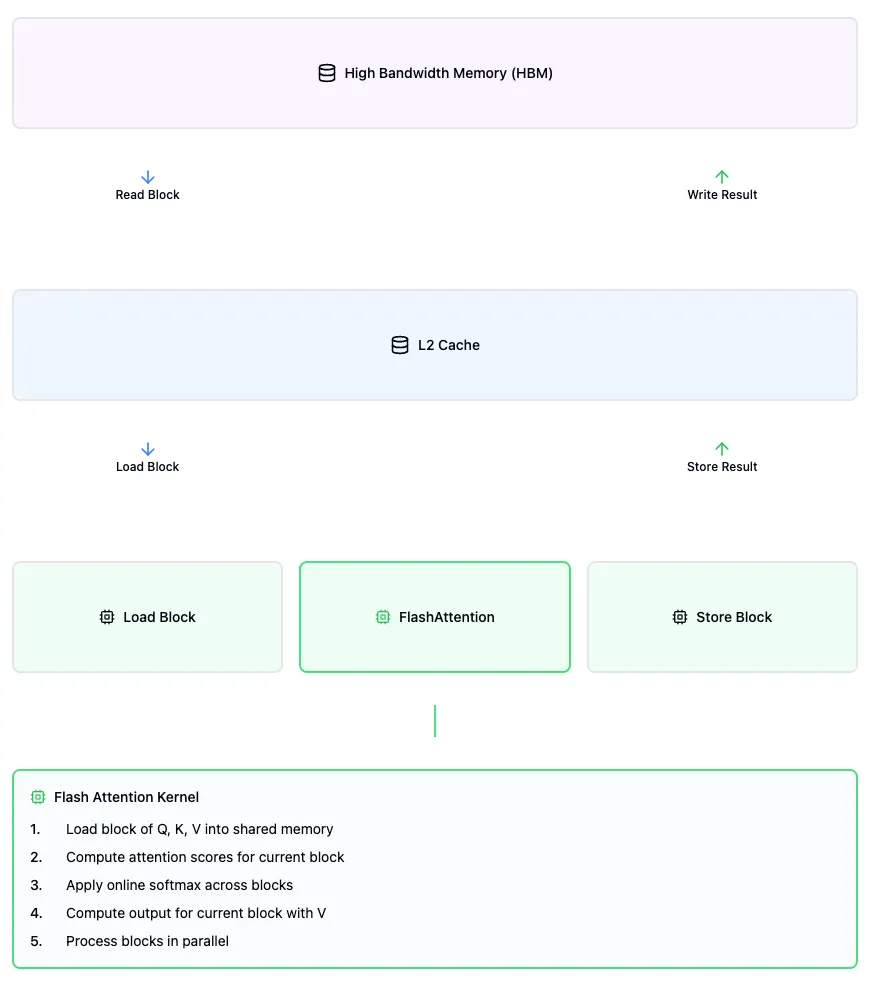
Simplified Flash Attention with fused kernel.
However, modifying FlashAttention's behavior -- such as applying tanh to the attention score matrix (Query-Key product) or implementing sliding window attention -- required inserting new steps into the fused kernel. This meant researchers had to write custom low-level GPU code, undermining FlashAttention's ease of use.
FlexAttention solves this problem by exposing two APIs that maintain the performance benefits of fused kernels:
score_mod: An API that allows modification of the attention scores after the Query-Key matrix multiplication. This matrix transformation is integrated into the fused kernel, preserving FlashAttention's computational efficiency.
mask_mod: An API that enables efficient masking patterns using negative infinity values. The attention matrix is processed in blocks (regions of tokens), and entire blocks can be skipped when masked. Common applications include:
Causal attention (masking all blocks of tokens that come after the current position)
Sliding window attention (only processing blocks within a fixed distance)
Sparse attention patterns (skipping blocks based on custom patterns)
The mask_mod optimization is particularly efficient because it works at the block level. When a block is masked with negative infinity values, those values become zero after softmax. This allows FlexAttention to completely skip loading or computing those blocks, effectively treating masked regions as non-existent. This block-wise selective computation significantly increases throughput while maintaining mathematical correctness.
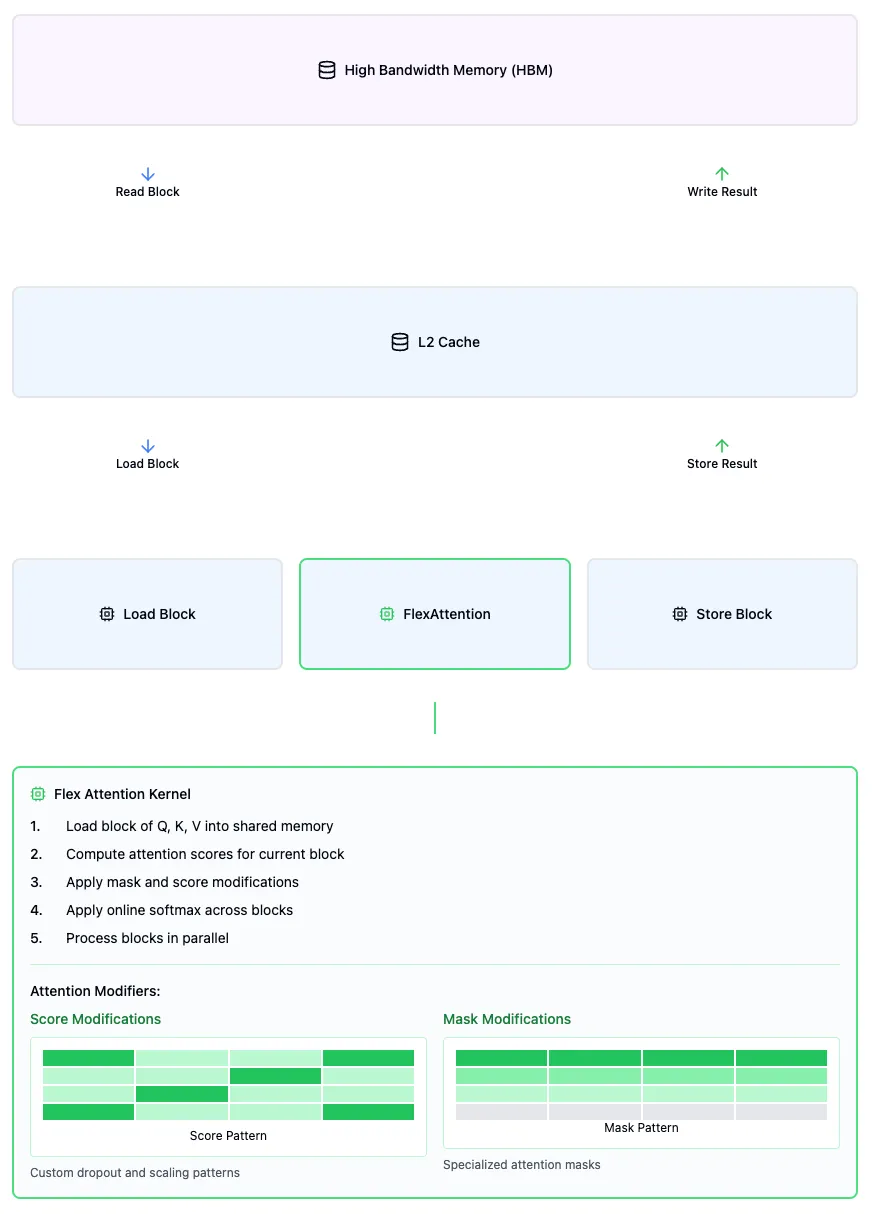
Simplified Flex Attention with fused kernel including score and mask mods.
The score_mod function, with signature score_mod(score, b, h, q_idx, kv_idx) -> float, allows direct manipulation of attention scores. Here, score is the Query-Key dot product, b is the batch index, h is the head index, and q_idx/kv_idx are the query and key-value position indices. This enables position-aware transformations like score * exp(-abs(q_idx - kv_idx)).
The mask_mod function, with signature mask_mod(b, h, q_idx, kv_idx) -> bool, determines which positions participate in attention -- True includes the position, while False masks it. This enables patterns like causal masking through simple conditions like q_idx >= kv_idx.
While score_mod could technically implement masking by returning very negative numbers, mask_mod is specifically optimized for binary patterns, resulting in more efficient compiled kernels.
FlexAttention requires torch.compile, PyTorch's system for converting high-level code into optimized computational graphs. Through compilation, operations are transformed into lower-level representations where both individual steps and their combinations can be optimized for specific hardware targets. In FlexAttention's case, this compilation allows the score_mod and mask_mod functions to be fused into efficient GPU kernels at runtime, preserving the flexibility of Python-level modifications while achieving performance close to hand-written CUDA code. FlexAttention kernels utilize Triton under the hood -- a framework that enables custom GPU kernels to be written using Python-like syntax, bridging the gap between high-level Python and low-level GPU programming.
A major limitation is that FlexAttention's flexibility is limited to modifications made to the attention score matrix (the product of Query and Key matrices). Techniques that modify other parts of the attention mechanism, such as modifying Query and Key matrices before score computation (as in RoPE2D), cannot be fused into the kernel.
An advantage of FlexAttention is that no recompilation is needed as long as the computation graph's structure remains consistent. Once the operations are lowered to a fused kernel, only the tensor values -- not their patterns -- need to change. While we may need to recompute the specific score_mod or masking patterns based on input tensors, we won't need the expensive process of recompiling our code for each pass.
For repeated applications of the same mask or score modification, caching these patterns can further improve performance by avoiding redundant computations.
However, FlexAttention faces challenges with dynamically changing computation graphs, such as in sliding attention with changing input sequences. While a fix exists to convert dynamic input sizes to static ones, the fundamental limitation remains: kernels cannot be efficiently fused when their computational patterns keep changing. Recompilation at each step would be prohibitively expensive.
When incorporating trainable parameters into the score_mod function, particularly in the context of dynamic input sizes, we face significant challenges related to tensor broadcasting and gradient backpropagation. The issue arises when a learned bias parameter needs to be broadcast across attention scores of varying sequence lengths. In such cases, we must carefully track the broadcasting pattern during the forward pass to ensure correct gradient accumulation back to the bias parameter during backpropagation.
Broadcasting a bias across varying input sizes means that the shape and dimensions over which the bias is applied can change dynamically. During the backward pass, this requires careful management of reduction operations to correctly aggregate gradients across expanded dimensions back to the original bias parameter shape. The complexity is compounded with dynamic input sizes because the reduction patterns can vary with each iteration, making it challenging to implement efficient and accurate gradient computations.
FlexAttention currently does not support this level of dynamic tracking and gradient reduction for trainable parameters within score_mod. The fused kernel is optimized for fixed computation graphs and static input sizes, and cannot handle dynamic broadcasting patterns that change during runtime. This limitation makes it impractical to include trainable parameters in score_mod, as gradient reductions cannot be reliably performed, and the benefits of kernel fusion would be negated by the overhead of handling dynamic computations.
FlexAttention is currently optimized for block sizes of 128 and their multiples. The additional memory cost for score_mod and mask_mod operations is relatively small, scaling with (sequence_length)^2/(block_size)^2, since sequences are stored in block-sized chunks. While smaller blocks could enable more fine-grained masking and region skipping, they introduce overhead from increased load operations, as each block must be loaded separately.
Current development efforts focus on extending FlexAttention to distributed training regimes like Fully Sharded Data Parallel (FSDP). This requires careful consideration of how to share not only model parameters but also the score_mod and mask_mod computations across devices.
FlexAttention embodies PyTorch's foundational philosophy of flexibility and accessibility, which has made PyTorch particularly valuable within research contexts where custom architectures are common. This presents a key challenge: maintaining PyTorch's fundamental components -- tensors and their operations, autograd for automatic differentiation, and essential data structures for model state and buffers -- while supporting an expanding range of devices, architectures, and training approaches (distributed or otherwise). The limits of machine learning research are often engineering rather than theoretical, making PyTorch's ability to implement diverse techniques crucial. FlexAttention embodies this challenge -- to be more useful than just a custom kernel and gain widespread adoption, it needs to support a broad range of attention implementation patterns and deployment scenarios. This led to the creation of AttentionGym, a comprehensive testing environment where users can experiment with FlexAttention implementations, run performance benchmarks across different scenarios, and share validated use cases with other practitioners, ensuring the core product can evolve to meet the community's needs.
FlexAttention bridges the gap between FlashAttention's performance optimizations and researchers' need for customizable attention mechanisms. Through score_mod and mask_mod APIs, enable experimentation with custom attention patterns while preserving the efficiency of fused kernel operations. Current constraints include specific GPU hardware compatibility requirements, block sizes optimized for 128 tokens, and the need to define patterns at compilation time. Despite these limitations, FlexAttention demonstrates how to balance high performance with implementation flexibility. As development progresses, especially in distributed training scenarios, these solutions for efficient customizable attention are likely to influence the future evolution of attention mechanism implementations.