X-Raying Multi-head Attention
Understanding the Need for Diversity in Heads.
At the heart of transformer models lies a peculiar redundancy: dozens of attention heads in each layer, all seemingly performing similar tasks. While conventional wisdom suggests these multiple heads help capture diverse relationships between tokens, mounting evidence shows many of them may be superfluous. Understanding why, and how many heads we truly need, could reshape how we build these models.
Role of MultiHead Attention
The general idea behind having multiple heads is that since each token (representing a word, sound, or pixel) can interact with its context (the surrounding tokens) in various ways, a single attention head might only capture part of this interaction. By having multiple heads with different random initializations, we increase the chances that these attention heads’ parameters (the query, key, and value matrices) diverge during training and capture the diversity of these interactions.
Now, the bulk of the computational cost for large context lengths, , in a transformer model stems from the attention heads, which have complexity. This means that if an additional head doesn’t lead to a significant increase in performance, as one might expect, it may not justify the extra cost incurred. This is why an architecture like DeLight, which aims to redistribute attention heads efficiently, is important.
Research shows that only some attention heads in a layer might look at different information. Indeed, most heads in a transformer can be dropped entirely without significantly decreasing model performance, and a handful of heads contribute the most to the performance. This even led to a paper on a technique called drophead regularization, which involves dropping entire - seemingly redundant - heads during training. It is beneficial to understand how diversity within attention heads impacts training and how this diversity helps different layers of a transformer learn with less redundancy.
Quantifying Diversity
The question arises: how do we quantify “diversity” in attention heads? We can turn to a different area of literature, focused primarily on encoder-decoder models for machine translation tasks, which aimed to introduce inductive biases to improve transformer training performance by incorporating orthogonal regularization.
Since machine translation primarily benefits from diverse contexts, leading to better translations, these papers supplemented standard training loss functions like cross-entropy with regularization terms that would measure how orthogonal the attention heads or the vectors produced by them are. When models train, the attention heads diverge more and are less overfit based on patterns in the training data. This approach leads to slightly better scores on metrics like BLEU within machine translation and other encoder-decoder use cases. However, these metrics have not been deployed on decoder-only models (and based on my experimentation with these regularization techniques for decoder-only models, they do not seem to help much, if at all). Nevertheless, these regularization terms have been shown to change during training even with standard loss functions and are good metrics to measure attention head diversity.
We will use four metrics to measure the diversity of heads in our modified MultiHeadAttention module: inter-head orthogonality, inter-head context vector non-orthogonality, inter-head output dissimilarity, and intra-head attention diversity.
1. Inter-Head Orthogonality
This metric assesses the degree of orthogonality between the query vectors from different attention heads. It ensures that each head attends to distinct aspects of the input data by measuring how similar or different their query directions are. Lower values indicate higher orthogonality, showing that the heads capture unique features or patterns from the input, which enhances the model’s ability to generalize across different parts of the data.
High -> Low Diversity
and are the query matrices of heads and .
2. Inter-Head Context Vector Non-Orthogonality
This measure quantifies the similarity between the context vectors produced by different heads. Context vectors result from the attention mechanism’s input data aggregation based on learned importance weights. High values in this metric suggest redundancy among heads, indicating that they focus on similar information instead of complementing each other. Unlike orthogonality in queries, which aims to ensure that different heads look to varying aspects by checking how independent their directions are, this metric examines how much the results produced by different heads overlap. This focus on the collective impact rather than just directional differences helps to understand the extent of similarity in their contributions.
High -> Low Diversity
and are the context vectors from heads and . Correction: The variable name should be inter-head, not intra-head.
3. Inter-Head Output Dissimilarity
This metric captures the dissimilarity in the outputs from different heads. Evaluating the negative average of the cosine similarity between each pair of head outputs provides insights into the diversity of the information each head contributes to the final model output. Greater dissimilarity suggests that the heads are processing and contributing varied aspects of information, enhancing the model’s robustness.
High → More Diverse
and are the output vectors of heads and .
4. Intra-Head Attention Diversity
This metric evaluates how the attention is distributed within each head over different input positions. It calculates the variance of attention weights, reflecting whether the attention is focused on a few positions or spread out across many. Higher variance suggests a dynamic attention pattern that adaptably focuses on different relevant parts of the input depending on the context. In contrast to other metrics calculated between attention heads, resulting in a matrix shape of , intra-head attention is specific to each head and produces a vector of length .
High → More Diverse
represents the attention weights for head .
Analysis
These charts use data from a decoder-only model using causal masking that has 8 heads in each layer and is comprised of 6 layers, utilizing a dropout rate of 0.1. Data for other model configurations is consistent and can be accessed in the source repository.
The first three metrics in the graph are displayed on a logarithmic scale because the metric values in the initial layer vastly exceed those in subsequent layers. Employing a relatively high learning rate of 0.01 and a batch size of 32, it’s noticeable that the metrics stabilize around the 10th epoch, coinciding with when the loss typically converges.
Notably, the first layer exhibits significant variation in its weights through attended position disagreement but shows the least orthogonality, indicating a substantial divergence within the matrices of the attention head. This observation aligns with the hypothesis that the initial layer primarily extracts generic features from the data. Despite the apparent lack of diversity, this layer has been identified as important to transformer performance and the last to be pruned. This idea of low orthogonality in the first layer might be supported by “The Bottom-Up Evolution of the Transformer,” by Voita et al which I highly recommend reading to understand how token representations evolve through the layers. According to figures 5 and 6 in the original paper, token representations from layer 0 remain substantially closer to their initial state than those processed in higher layers; the layer is focused on data extraction rather than processing.
This makes me curious if this suggests that the first layer of transformers in language models has its version of a “Gabor filter” that appears in the early layers of most vision transformers.
It’s worth noting again that the first layer stands out from all other layers due to its very low orthogonality, which is why the graphs below are presented on a logarithmic scale. Since this layer is used for essential feature extraction, it would be interesting to see how this might differ for other data formats where the structure varies significantly from text.
Inter-head output dissimilarity across heads.
Change in batch loss as training progresses.
Interestingly, while attention diversity appears to stabilize in the first layer throughout training, it keeps increasing in several later layers as batches progress. This pattern suggests that attention diversity may be a poor predictor for model performance.
Change in metrics by layer as training progresses. First 3 metrics are on a log scale.
Change in various metrics as training progresses. First 3 metrics are on a log scale.
Although batch loss and head diversity are closely correlated in the initial epochs, it’s better to view them as separate outcomes of the learning process for attention weights rather than attributing higher batch loss directly to increased head diversity. For the first 40 batches in layer 0, the head output disagreement means, and variance yields an R² of around 90%, demonstrating high predictive power, although this decreases in the later layers.
As training continues, orthogonality between heads decreases across all layers while output disagreement rises, including the variance of output diversity between heads. The heads learn to focus on the same subspaces. Still, the increasing variance suggests slight differences in how they focus on these subspaces, allowing richer representations of the information regarding the input tokens.
Change in mean and variance for inter-head orthogonality as training progresses.
There is a notable contrast in the level of disagreement among the outputs from different heads across the layers, as illustrated below. The initial three layers generate distinctly different outputs, whereas the representations in subsequent layers become increasingly similar. Voita et al. further demonstrate that most of the mutual information concerning the predicted token accumulates in the earlier layers (as shown in Figure 2 of the paper), with the later layers contributing only minor modifications to the target representation.
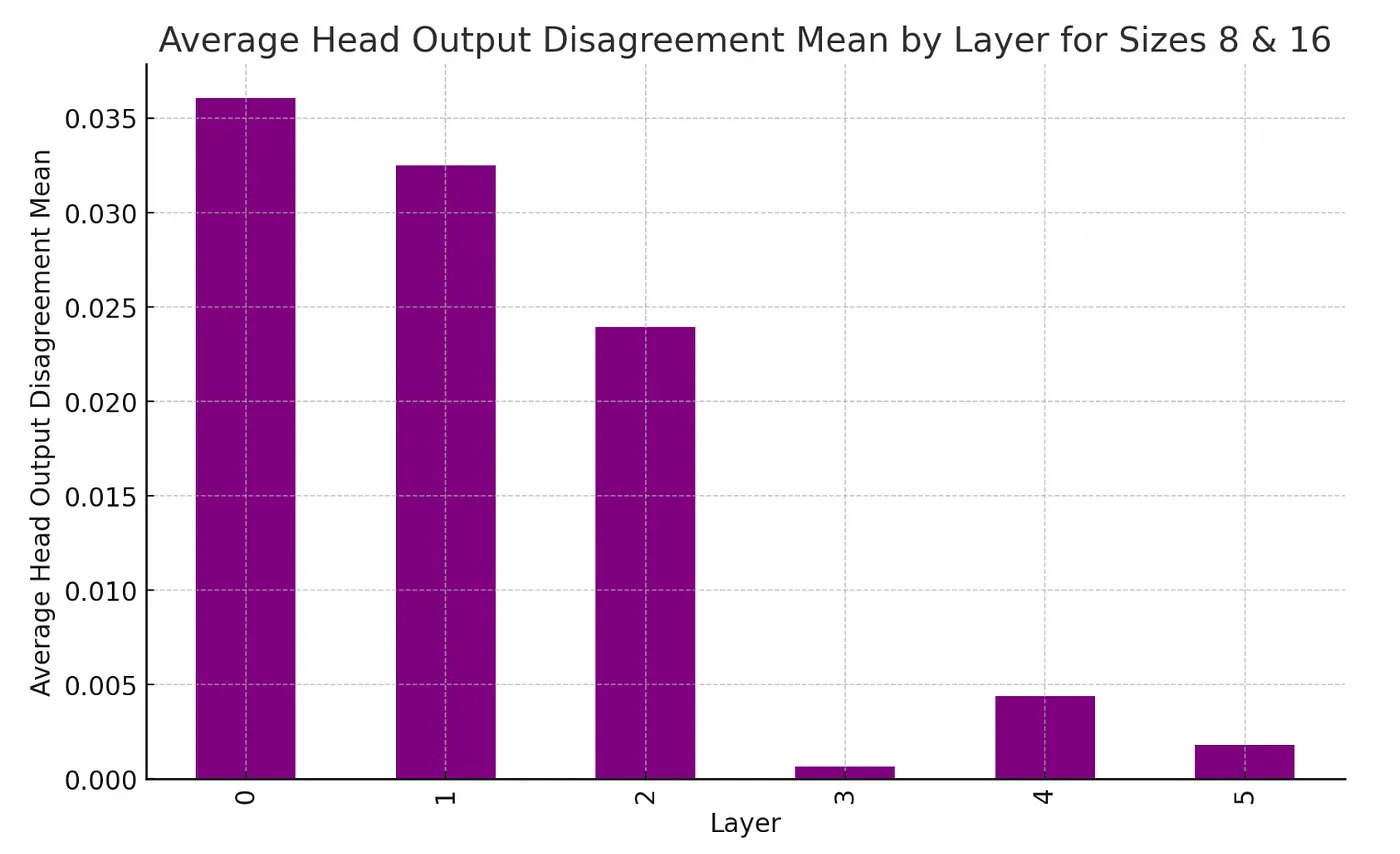
Average Head Output Disagreement across layers.
The head-by-head comparison in the gif below shows that heads in the last layers exhibit considerable similarity (indicated by shades of red). This similarity likely contributes to why, as shown in the 2019 study “Analyzing Multi-Head Self-Attention,” these heads are often the first to be pruned due to redundancy in their representations.
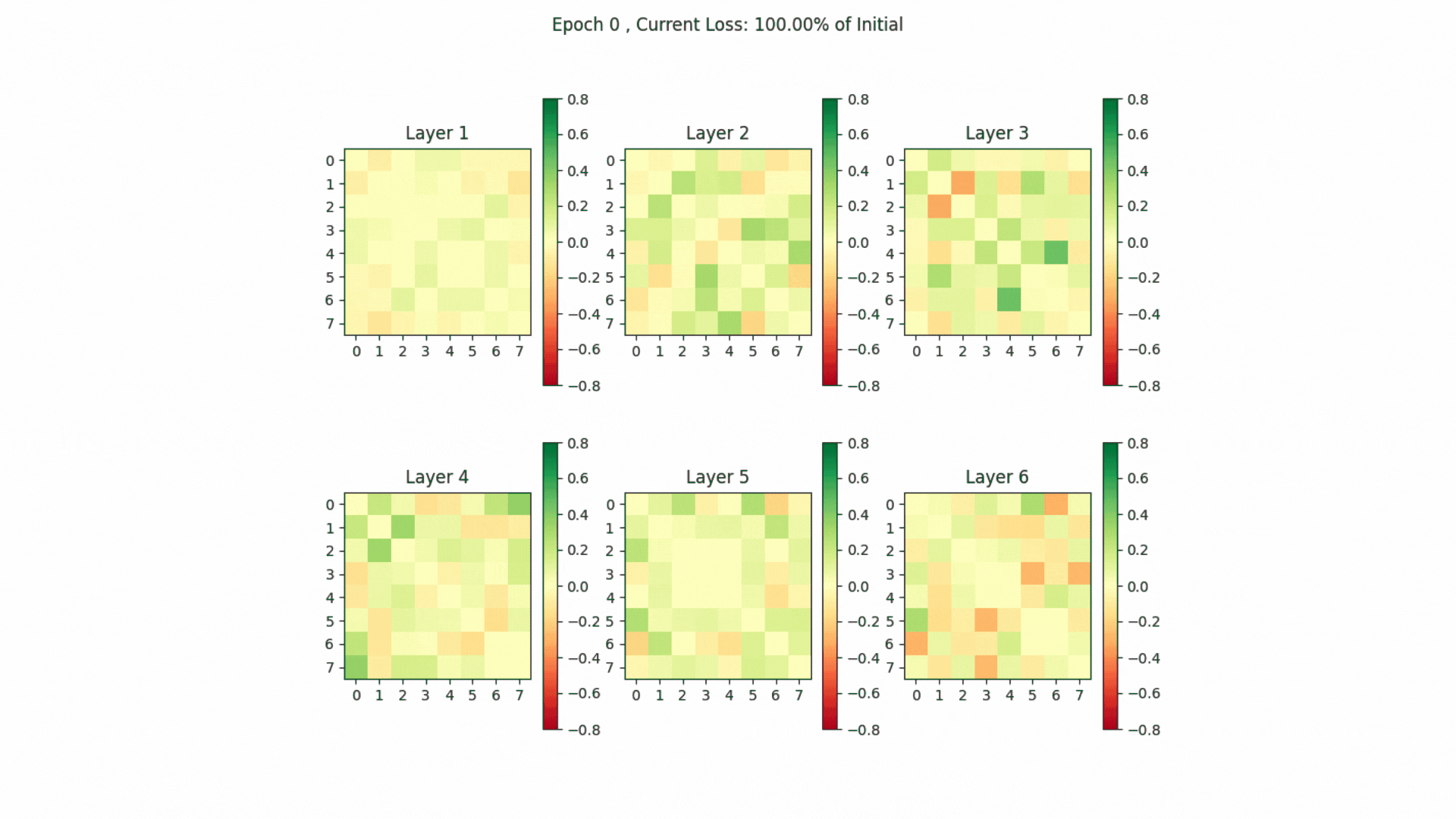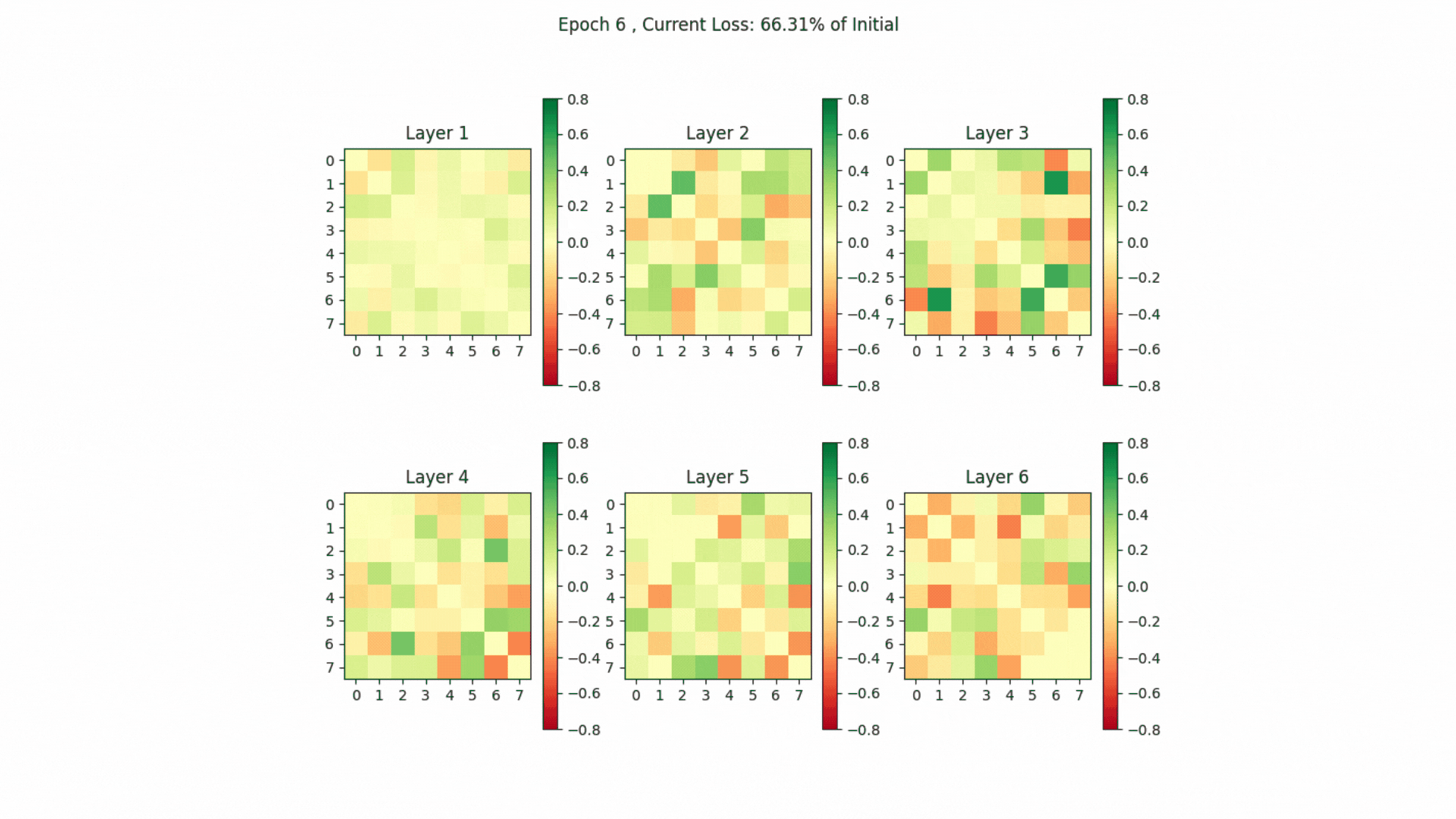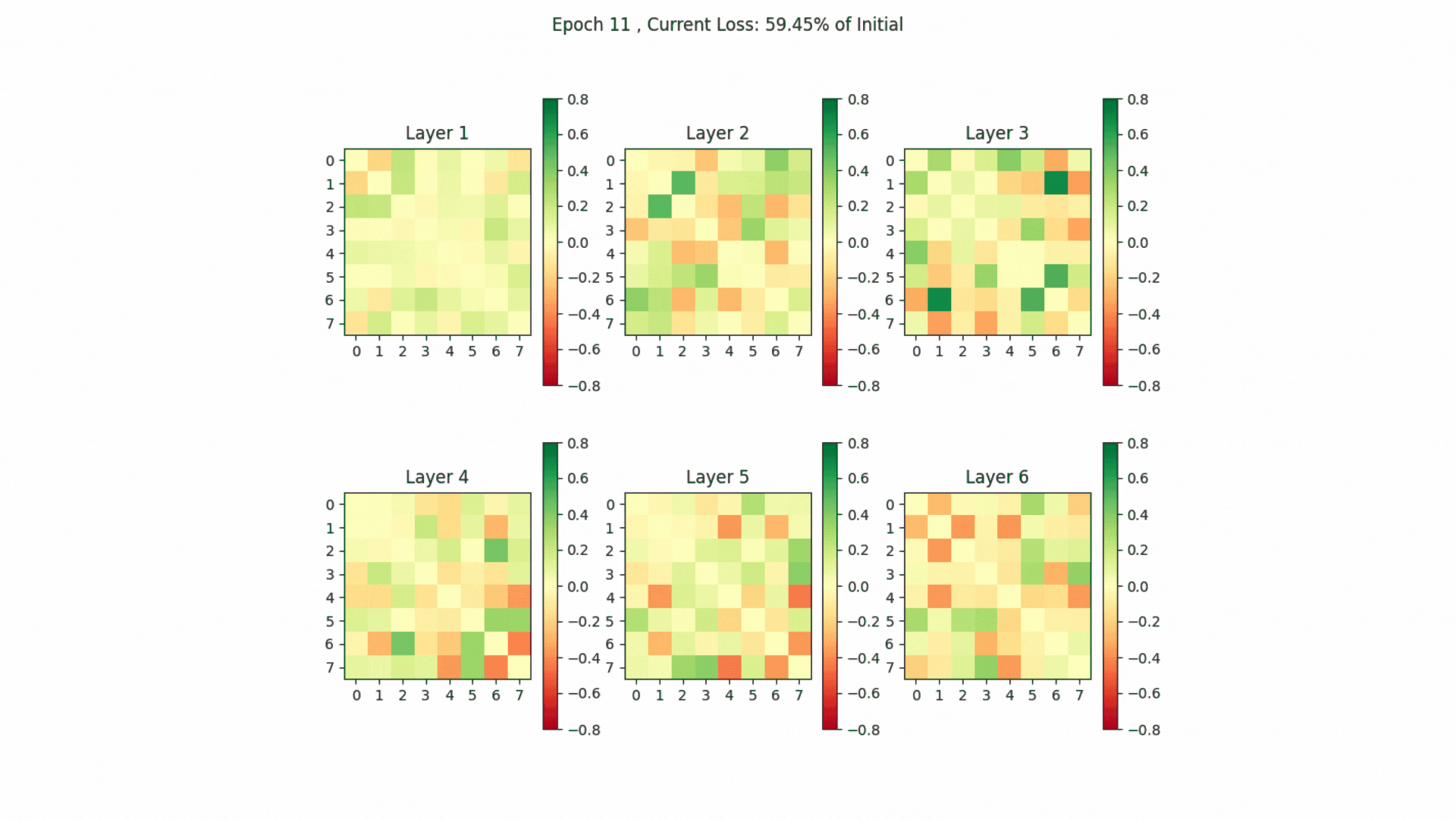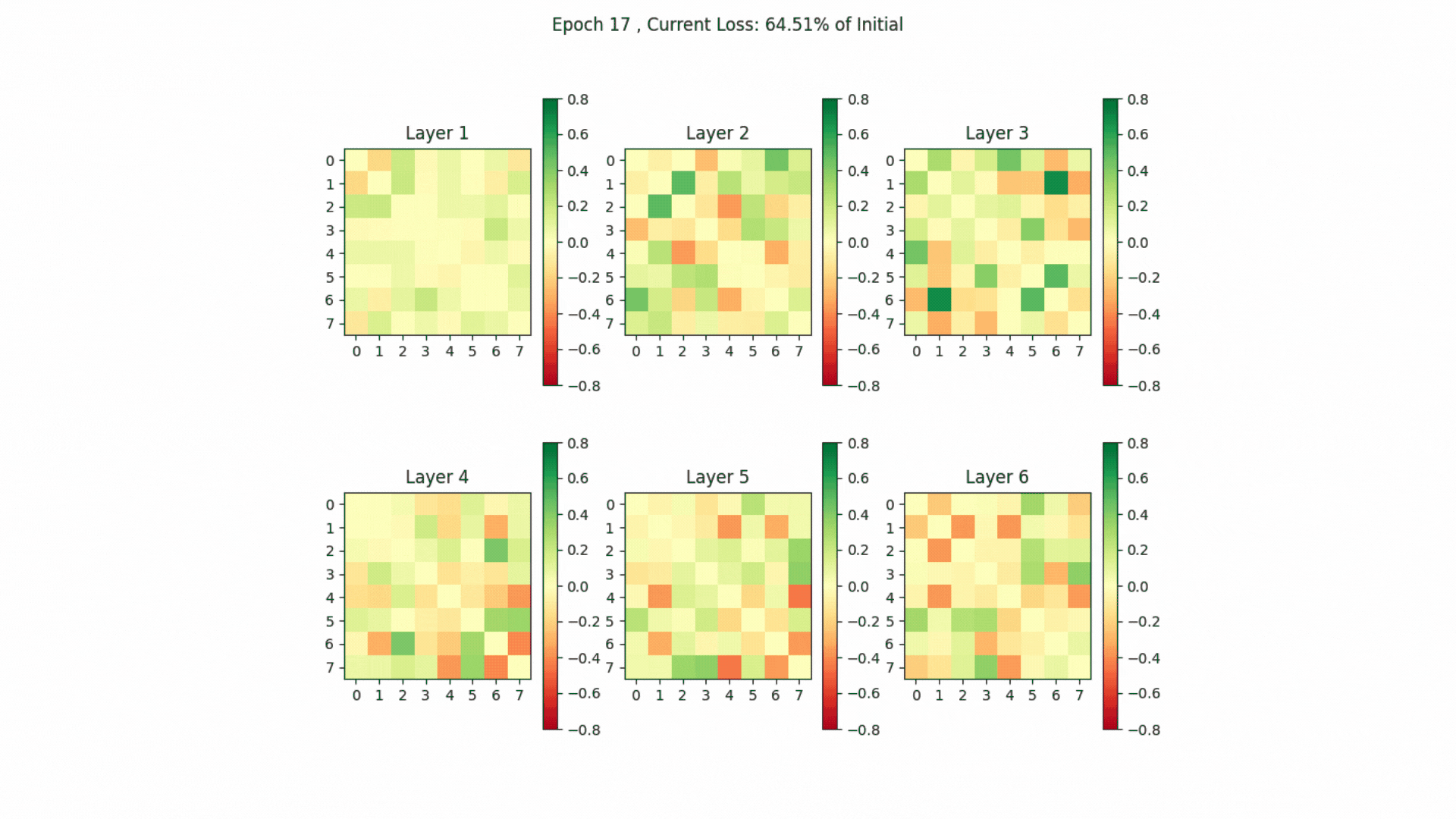
Change in Head Output Disagreement between specific heads.
Further Work
Measuring the diversity of representations created by heads in multi-head attention yields intriguing results that support existing research on how heads contribute to diverse data representations. Although my analysis focused on decoder-only attention, where future tokens are masked, it would be interesting to compare these findings with other architectures, such as machine translation or encoder-decoder models, as well as other forms of attention like Grouped-Query Attention. For example, is there a reason why orthogonality-inducing regulation techniques work better for machine translation than decoder-only models? While transformers are a powerful architecture, their strength lies in their scalability, which increases layers and attention heads, enhancing performance.
References
- Lee, Mingu, et al. “Orthogonality Constrained Multi-Head Attention for Keyword Spotting.” arXiv.Org, 10 Oct. 2019, arxiv.org/abs/1910.04500.
- Li, Jian, et al. “Multi-Head Attention with Disagreement Regularization.” arXiv.Org, 24 Oct. 2018, arxiv.org/abs/1810.10183.
- Mehta, Sachin, Marjan Ghazvininejad, et al. “Delight: Deep and Light-Weight Transformer.” arXiv.Org, 11 Feb. 2021, arxiv.org/abs/2008.00623.
- Mehta, Sachin, Mohammad Hossein Sekhavat, et al. “OpenELM: An Efficient Language Model Family with Open Training and Inference Framework.” arXiv.Org, 2 May 2024, arxiv.org/abs/2404.14619.
- Michel, Paul, et al. “Are Sixteen Heads Really Better than One?” arXiv.Org, 4 Nov. 2019, arxiv.org/abs/1905.10650.
- Voita, Elena, David Talbot, et al. “Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.” arXiv.Org, 7 June 2019, arxiv.org/abs/1905.09418.
- Voita, Elena, Rico Sennrich, et al. “The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives.” arXiv.Org, 3 Sept. 2019, arxiv.org/abs/1909.01380.
- Zhou, Wangchunshu, et al. “Scheduled Drophead: A Regularization Method for Transformer Models.” arXiv.Org, 1 Nov. 2020, arxiv.org/abs/2004.13342.