Efficient Transformers
Combining Grouped-Query Attention with Mixture of Depths
Introduction
The similarity between you and a big Artificial Intelligence research organization (aside from a few dozen thousand GPUs) is that, ultimately, your models will likely be subject to the same scaling laws. At some point, the quest for creating more accurate, and larger transformer models becomes constrained by the practical costs, no matter how much funding you have. The cost is associated with three key ingredients: data, compute resources, and model parameters, although qualitative differences in these also matter. In practice, slaying this triple-headed hydra can be a trade-off, where more model parameters typically necessitate more data, which in turn requires more computing power for training.
A significant bottleneck for model development lies in the compute resources, explaining why chip design and manufacturing are booming currently. However, employing more computing resources is, in some sense, a brute-force approach, and significant strides are being made in research to make existing architectures more efficient. Two promising methods in this regard are Google's recent Mixture of Depths and Grouped Query Attention techniques. In this implementation, I combine the Grouped Query Attention (GQA) and Mixture of Depths (MoD) techniques for the first time in a hybrid approach for a small transformer model. This first hybrid combination of these methods achieves approximately 70% faster training speed than a standard decoder-only model, with a 10% higher perplexity as a trade-off.
Cost of the even "Larger" Language Model
The number of operations in a transformer layer can be expressed as:
Where:
- : Number of heads in the multi-head attention mechanism.
- : Sequence length (number of tokens in the input).
- : Model embedding size.
- : Dimensionality of the key and query in the attention mechanism.
- : Dimensionality of the feed-forward layer.
A transformer model can be scaled up by increasing the number of attention heads, adding more layers, expanding embedding dimensions, or enlarging the dimensions of the feed-forward layers. However, the attention layer is the most significant cost factor in training a transformer model.
For a given sequence length of tokens (context length), the attention mechanism involves representing the context using query and key matrices and computing their dot products. This results in computational operations. As models scale up to handle larger context lengths and integrate more significant parts of text or image data into decision-making, the attention layer has proven to be the primary bottleneck. Practically, for small , the feed-forward network (FFN) layer costs can exceed that of the attention layer.
Overcoming this bottleneck has been a crucial target for faster training speeds through methods like sparse attention. Recent techniques like Mixture of Depths (MoD) and Grouped Query Attention (GQA) have aimed to cut down on training times while maintaining the high accuracy of standard transformers.
Grouped-Query Attention
We employ multiple attention heads in each attention layer to manage various representations of a single token within a transformer. Each head, with its distinct set of randomly initialized query, key, and value matrices, might capture different aspects of a word, enabling us to derive a more nuanced representation of words. For instance, a large model like GPT-3 utilizes 96 attention heads per layer, with the dimensions of these matrices scaling with the model’s size.
The Grouped Query Attention (GQA) approach modifies this using the same key and value matrices across multiple query heads, reducing the number of trainable parameters. Additionally, it reduces memory overhead for the attention computation by loading each unique key or value matrix only once, not to mention a reduction in the size of the KV cache. This strategy simplifies the computation within the multi-head attention mechanism by reducing the redundancy in transformations applied to K and V. This reduction in complexity can lead to improvements in throughput and latency, albeit at the potential cost of decreased model accuracy. A single KV head results in the fastest performance (Multi-Query Attention) and low accuracy, while when the number of KV heads is the same as the number of query matrices, accuracy and speed are identical to standard multi-head attention. A perfect tradeoff between speed and accuracy is achieved for some intermediary number of KV matrices.
Mixture of Depths
In a model like Llama 3, where an attention head may handle up to 8000 tokens, not all tokens are equally useful for predicting information about the next token.
As proof: Llama 3 attention head, not 8000 tokens equally useful predicting next.
This router layer, applied every two attention blocks, learns to only allow a subset of important tokens to participate in each transformer block (the authors of the paper recommend 12.5%). While adding a router layer increases the operations per MoD block by , it significantly reduces the computational load in the attention head to a fraction of . Moreover, it also cuts down the FFN layer computations by a factor of , further reducing training times. This improvement makes the training or inference process considerably faster, and since we focus only on the valuable tokens, the loss in model performance for this increase in speed is small.
Hybrid Model
In the following Pytorch implementation, I modified code from this Grouped-Query Attention implementation by Frank Odom and this Mixture of Depths implementation by George Grigorev, using GQA attention for transformer blocks and wrapping each transformer block within a MoD block, which adds a router to every other layer. Dropout and causal masks are handled using the modified GQA attention mechanism.
These modified layers were used to create small 1–4 Million parameter decoder-only transformer models with 64, 128, 256, and 512 token lengths for (hey, I'm trying to run this off a Google Colab notebook), with other model attributes remaining the same. The time taken to train each model for 3 epochs and the perplexity as the performance measure for each model was recorded. It is worth noting that while perplexity serves as a measure of how well the model learns, its correlation with actual task performance is often non-linear. In other words, changes in perplexity may not consistently translate to linear improvements in task performance.
I used 8 query heads, 2 key and value heads. The MoD layer had a 25% pass-through rate, which is higher than the 12.5% recommended by the original MoD paper and therefore slower but offers a more suitable accuracy for a small model like mine (fig 3 in the original paper). My primary focus here was on training speed, while inference speed, which dominates training cost for most deployed models, was not studied.
For comparison, I created a "vanilla" decoder-only transformer and GQA and MoD implementations. These are special cases of the hybrid MoD-GQA that we can implement by setting the right hyperparameters. When the number of Key-Value (KV) heads equals the number of query matrices, we essentially recover the standard multi-head attention with unique query, key, and value matrices. Likewise, when the pass-through rate for the MoD block, , is 1, we never initialize the router layer, so it becomes a standard transformer block. We use the following configurations to replicate each model type:
- : Standard
- : GQA
- : MoD
- : Hybrid (referred to here as the Frankenstein architecture)
Results
The impact of these techniques on parameters is straightforward and can be seen from the results. In the implementation, as is convention, the number of parameters of the query, key, and value matrices are the same, denoted as . This dimension is typically calculated as the embedding size divided by the number of query heads . The other dimension is the sequence length . Therefore, the size of each query, key, and value matrix is , and the number of fewer parameters due to GQA is this size times per layer. The MoD's router layer increases the parameters by a factor corresponding to the sequence length . Both this reduction (GQA) and increase (MoD) scale linearly with , but the coefficients to the reduction are larger and tend to dominate. For a hybrid approach, the number of parameters is lower than that for a standard implementation.
Compared to the baseline performance of a standard transformer at 0, we can see below that MoD, GQA, and Hybrid approaches are significantly faster but lead to higher perplexity scores (less accurate). Hybrid approaches are consistently faster than both of these techniques, and the loss of accuracy is smaller for larger models. For a 512 context length model, the Hybrid approach is nearly 70% faster with only a 10% higher perplexity.
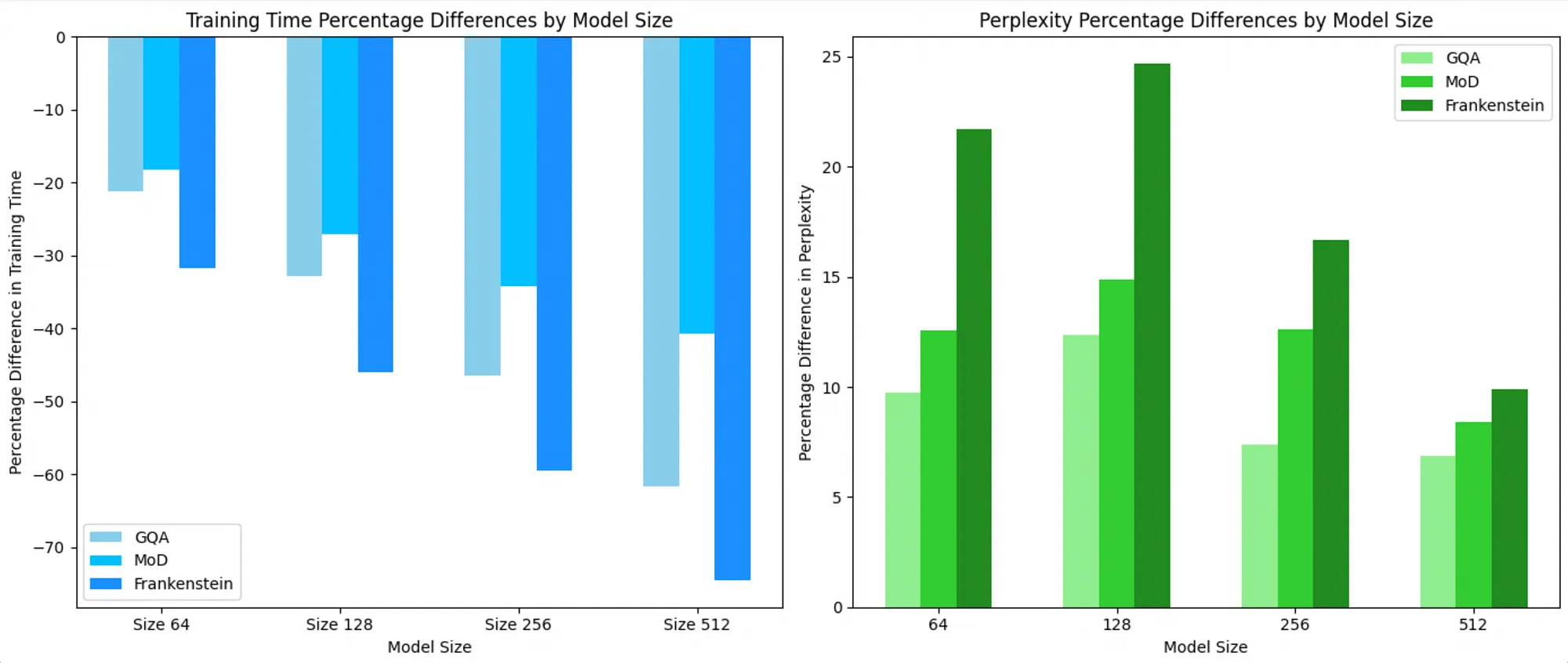
Model training speed and perplexities relative to the vanilla implementation for different model sizes of n.
Theoretically, MoD works on the router layer while GQA works on the attention layer so that we would expect no interactions between their effect. Using a simple OLS regression using Python's Statsmodel library, while we saw the additive effects of both techniques, the impact of an MoD-GQA interaction term on both the perplexity and training time is non-significant (p = 0.606 and p = 0.309), respectively (although with such few datapoints this might be as accurate as numerology). However, both techniques individually contribute to lowering training times and also lead to a reduction in accuracy.
For the largest model size with a sequence length of 512, we saw the closest performance in speed and accuracy to the hybrid architecture from a GQA approach, so I decided to "race" the two models in achieving lower training loss over 4 epochs. As expected, the hybrid architecture concluded training much earlier than the simple GQA approach. As seen from the graphs below, by its ability to process batches much faster, the hybrid approach can achieve much lower loss values than the GQA approach much earlier during training. The hybrid approach is generally 33% faster than the GQA approach, with only 2.8% worse perplexity. While it is less accurate, it can compensate for this by reaching the same loss value much earlier than the GQA. The graph below shows the percentage difference between training loss for the two approaches, with the hybrid training concluding at 214 seconds, with a positive difference showing GQA having a higher loss for the time point. We can see that for the first few epochs, the loss for the hybrid approach is significantly lower than that for GQA, and it is only after hybrid training has been completed that GQA catches up (the percentage difference between loss becomes 0 or negative). This suggests that even while it might increase perplexity slightly, the speed of the hybrid approach might make it worthwhile to use.
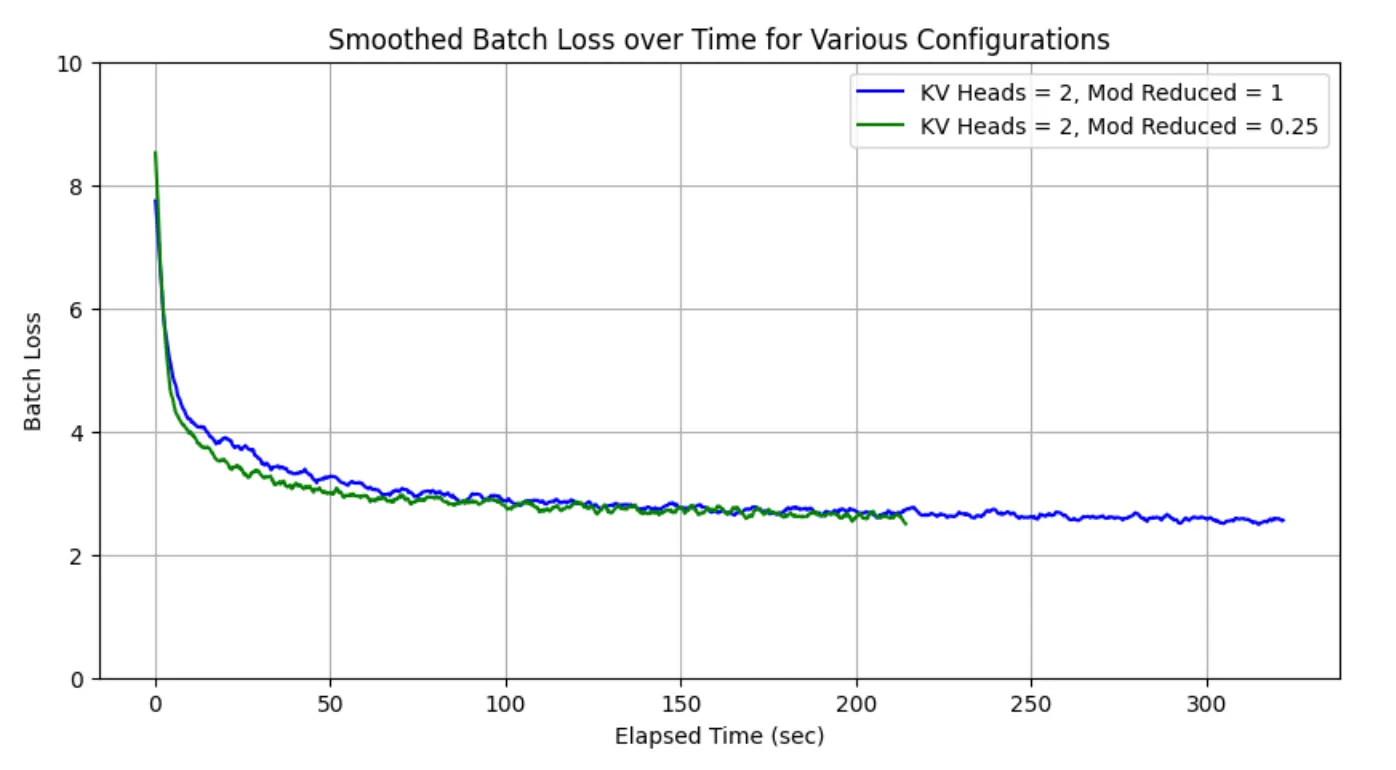
Training loss for the GQA and Hybrid approaches by batch over time. Hybrid achieves lower loss faster.
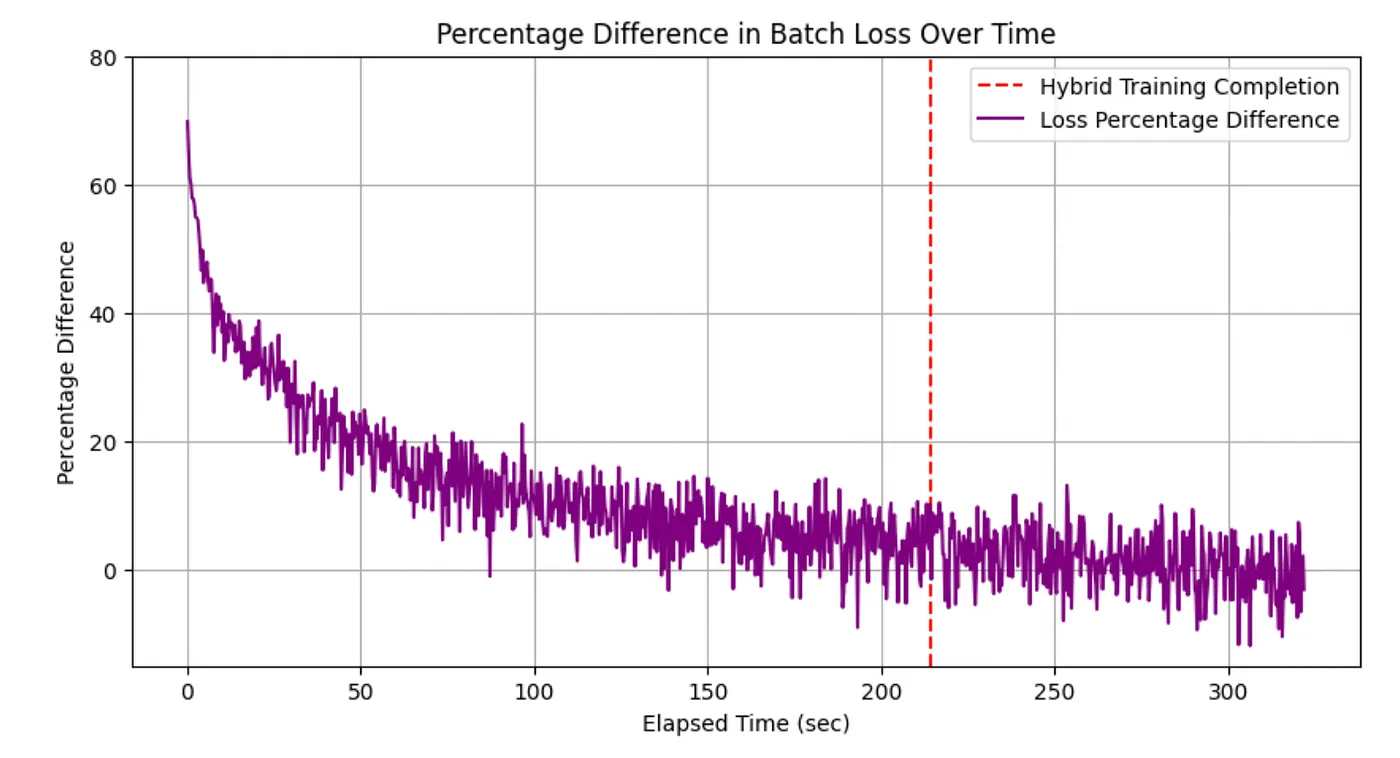
Percentage difference between loss from the GQA and Hybrid approaches. While GQA achieves a lower loss, it takes longer to achieve the same loss as the hybrid approach.
Since MoD achieves close to standard transformer loss values for even larger models, we can expect larger hybrid implementations to deliver similar results for speed with limited compromise in perplexity when applied to larger models, such as those used in actual deployments.
Conclusion
Testing this approach revealed that combining these two strategies results in latency far lower than using either approach individually. While the accuracy is also worse than each individual approach, it is not significantly lower than that for the individual MoD or GQA approaches. Models like Mistral 7B already use grouped query attention, and it might be worth further research to combine it with techniques like Mixture of Depths. This could be coupled with other efficiency techniques and techniques like KV cache, etc., to inspect the effect of this hybrid technique on inference times. I invite researchers and practitioners with access to greater computational resources to explore this hybrid approach and its feasibility further using larger models than I could make. As the quest for faster training of larger models continues, we can expect to discover new optimizations for both hardware and model architectures to achieve this goal.
References
- GQA Implementation by Frank Odom: https://github.com/fkodom/grouped-query-attention-pytorch/blob/main/grouped_query_attention_pytorch/attention.py
- MoD Implementation by George Grigorev: https://github.com/thepowerfuldeez/OLMo/blob/main/olmo/mod.py
- Shazeer, Noam. "Fast Transformer Decoding: One Write-Head Is All You Need." https://arxiv.org/abs/1911.02150
- Ainslie, Joshua, et al. "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." https://doi.org/10.48550/arXiv.2305.13245
- Fireworks.ai. "Multi-Query Attention Is All You Need." https://blog.fireworks.ai/multi-query-attention-is-all-you-need-db072e758055
- Raposo, David, et al. "Mixture-of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models." https://doi.org/10.48550/arXiv.2404.02258